
NVIDIAから、Ampereアーキテクチャの技術詳細についてのホワイトペーパーが公開されました。

NVIDIAはRTX 3080について、RTX 2080から最大2倍の性能を実現するとアピールしていますが、「ベンチマークスコアもfpsも2倍になってなくね?」という声もチラホラ。ということでホワイトペーパーを大まかに翻訳しつつ、一体何がTuringから2倍の性能なのかを見てみます。
なお文中のNVIDIAのスライドはTom’s Hardwareが掲載しているものから拝借。

RTX 30シリーズで「Turingよりも2倍速い」のはレイトレーシング処理速度
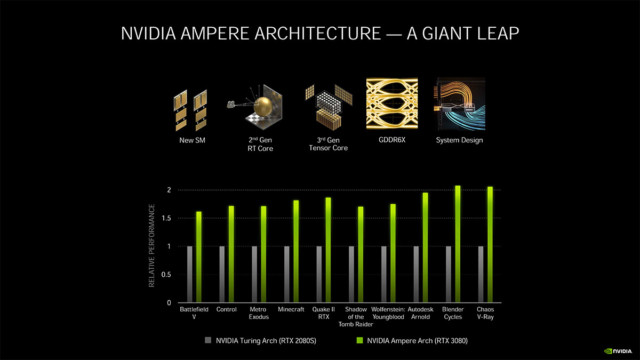
とは言ったものの、ホワイトペーパー冒頭で、AmpereアーキテクチャはTuringと比較して従来の(ラスター)グラフィックスワークロードで最大1.7倍、レイトレーシングワークロードで最大2倍の速度を実現しているといきなり答えがあります。
つまりTuringから2倍速くなったのはレイトレーシング処理速度で、既存のゲーム(ラスター)が倍のfpsで動くという話ではなかった。
流石にこれで終わりでは中身がなさすぎるので、ホワイトペーパーを大まかに読み解いていくと、ハードウェアとしては色々とTuringから2倍に拡張されているのが分かります。
今やGPUはPCで一番高価なパーツなので、どんなものを買っているのか理解して買ったほうが軽くなった財布に言い訳が立つ……気がする。
Turingをベースに改良されたAmpereアーキテクチャ
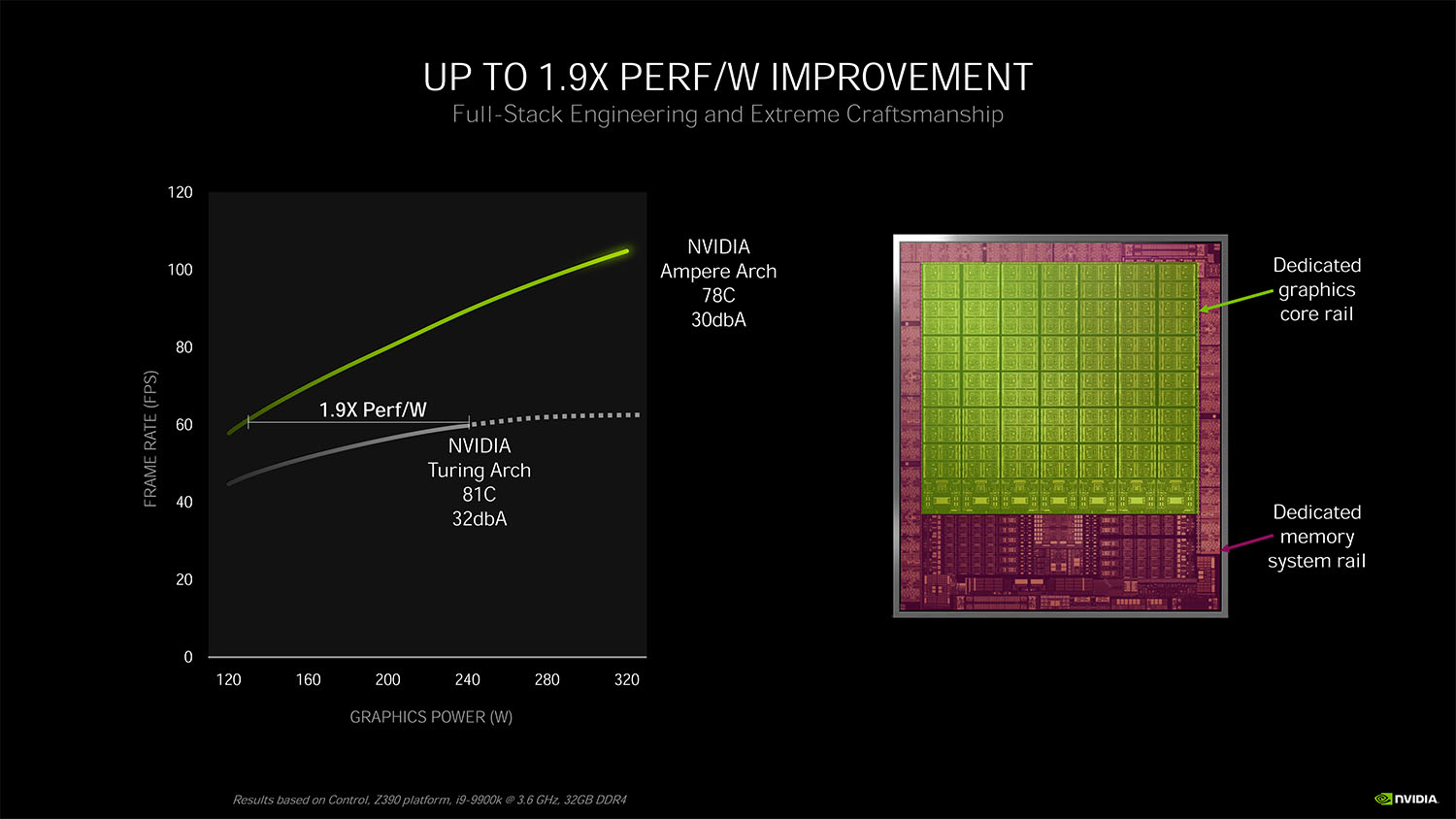
Ampereアーキテクチャでは、Turingをベースに多数の改良が施されており、NVIDIAはRTX対応の『Control』プレイ時の比較で、Turing世代では消費電力240 W / コア温度81℃ / ノイズレベル32dBで60 fpsだったのに対して、Ampereでは130 W / 78℃ / 30dBで100 fps以上で動作し、電力効率は1.9倍に改善されているとアピールしています。
これもRTX環境下での比較で、レイトレーシング+DLSS Onで1.9倍。
RTX 30シリーズだけでなく、HPC向けの「NVIDIA A100」も同じAmpereアーキテクチャの「GA100」を搭載した製品ですが、HPC用途とゲーミング/グラフィックス用途のGeForceでコアの構成が異なるので、全く同じではありません。

Turingの演算性能 Ampereの演算性能

トランジスタ実装密度が大きく高まったGA102
RTX 3090 / 3080に搭載されている「GA102」は、628.4 mm2のダイに280億のトランジスタを詰め込んでおり、Turingの同等GPU「TU102」が754 mm2に186億トランジスタの設計だったので、面積が小さくなると同時にトランジスタ数も増加。
TU102の1 mm2あたりのトランジスタ数は2,467万個 (24.67 MTr/mm2)であるのに対し、GA102は4,456万個 (44.56 MTr/mm2)で、トランジスタ密度は1.8倍へ向上しています。
製造プロセスはSamsung 8N
リーク情報では話が二転三転していた製造プロセスについては、Samsungの8 nmプロセスであることが明らかに。最上位のGA102に関してはTSMC製造もあり得ると思っていたので、全てSamsungに統一されたのはちょっと意外。
プロセスに関しては「Samsung 8N NVIDIA Custom Process」という謎の説明のため、単なるSamsungノードではないようですが、基本的にはSamsungの8 nmノードである8LPPベースと思われます。
先に書いたようにGA102のトランジスタ密度は44.56 MTr/mm2で、理論上のSamsung 8LPPの最高トランジスタ密度は61 MTr/mm2前後と見られるため、恐らくロジック密度については8LPUそのままの仕様。「NVIDIA向けの最適化」とやらは高電圧/高クロックの耐性あたり?
そもそも、Samsungの8 nmプロセスは10 nmの10LPEをベースとした派生プロセスのため、プロセスノードの世代としてはTSMCのN7やSamsung 7LPPよりも1世代前。とはいえTuringは12 nmなので、GA102のトランジスタ密度からも分かるように8 nmへシュリンクした効果は大きい。
なお、NVIDIA A100搭載の「GA100」は826 mm2のダイに542億のトランジスタを詰め込んだ(密度65.62 MTr/mm2)の怪物チップで、8LPUでは作れず、N7にせざるを得なかったのも納得。
ではAmpereの次世代はどのプロセスノードになるのかという疑問が浮かびますが、今回はAMDにTSMCの生産ラインを抑えられていたために、GeForce生産分が確保できなかったという背景から、噂では次期GPUのために膨大な規模のTSMC N5ラインをNVIDIAが予約しているという話があったりなかったり……
GA102のコア構成

話を戻すと、GA102の内部には、主なグラフィックス関連の処理ユニットを包括した「Graphics Processing Cluster (GPC)」というブロックが7つあり、各GPCの中に「Texture Processing Cluster (TPC)」×6、「Streaming Multiprocessor (SM)」×2、「PolyMorphエンジン」×1、「Raster Operators (ROPs)」が配置されています。
フルスペックのGA102の場合、GPC×7とメモリコントローラを備え、合計でTPC×42、SM×84という構成。
メモリコントローラは32-bitコントローラ×12(計384-bit)で、512 KBのL2キャッシュがそれと対に配置され、全体で計6,144KBのL2キャッシュを持ちます。
ROPsに関しては、今までメモリコントローラとL2キャッシュに紐付けられていたのに対して、AmpereではGPCに組み込まれたことで総数が増え、スキャンコンバージョンのフロントエンドとラスター演算のバックエンド間のスループット差が無くなりラスター演算性能が向上。MSAA処理やピクセルフィルレート、ブレンディングが高速になっているとのこと。


RTX 3090より上の「フルスペックGA102」も後々登場?
上で「フルスペックのGA102の場合」と書いたのは、RTX 3080はもちろん、RTX 3090でもGA102のフルスペックではないからで、RTX 3090ではフルスペックGA102からTPC×1、SM×2が無効化された状態になっています。
そのため、すべてのコアが有効化された完全版が「Titan RTXa」のような形で投入される可能性も無くはない。ありえるとしたらゲーム向けではなく「Quadro RTX 8100」とかになると思いますが。
ピークFP32性能を2倍にするためCUDAコアが倍増

中身の話に戻ると、Ampereで大きく手が加えられたSMには、FP32ユニット(CUDAコア)×128、INT32(32-bit整数演算)ユニット×64、FP64(倍精度浮動小数点演算)ユニット×2、レイトレーシング演算を行うRTコア×1、AI(ニューラルネットワーク)処理を行うTensorコア×4、256 KBレジスタ、テクスチャユニット×4、128 KB L1キャッシュが配置されています。
CUDAコアの定義については、NVIDIAとしてはFP32(単精度浮動小数点数)の演算ユニットをCUDAコアとしてカウントしている模様。
RedditのAMAによれば、TuringからFP32の演算スループットを2倍にすることは、3000シリーズのSMの主要な設計目標の1つであった(Tony Tamasi上級副社長, NVIDIA)とのことで、その目標を達成するため、AmpereのSMではFP32とINT32演算用の新たなデータパス設計が盛り込まれています。
SMは4つの処理ブロック(パーティション)を持ち、各処理ブロックにはFP32ユニット(CUDAコア)×32、INT32(32-bit整数演算)ユニット×16、Tensorコア×1が配置されています。
Amepreのデータパスのうち、1つはFP32ユニット16基が並んだFP32演算専用データパス、もう1つはFP32ユニット×16とINT32ユニット×16が並んだFP32/INT32演算データパスとなります。処理ブロックあたりで、32のFP32演算か、16のFP32演算+16のINT32演算の同時処理が可能。
ユニット構成からすると、32のFP32演算+16のINT32演算が可能なように思えますが、1つのデータパスにINT32とFP32の命令を同時に流すことはできないため、2つ目のデータパスは「クロックあたり32のFP32演算」、または「クロックあたり16のFP32演算+16のINT32演算の同時実行」のいずれかを選択する必要があります。
SMあたりで考えると、Ampereでは処理ブロック4基の合計でクロックあたり128のFP32演算、または64のFP32演算+64のINT32演算の同時実行が行えます。
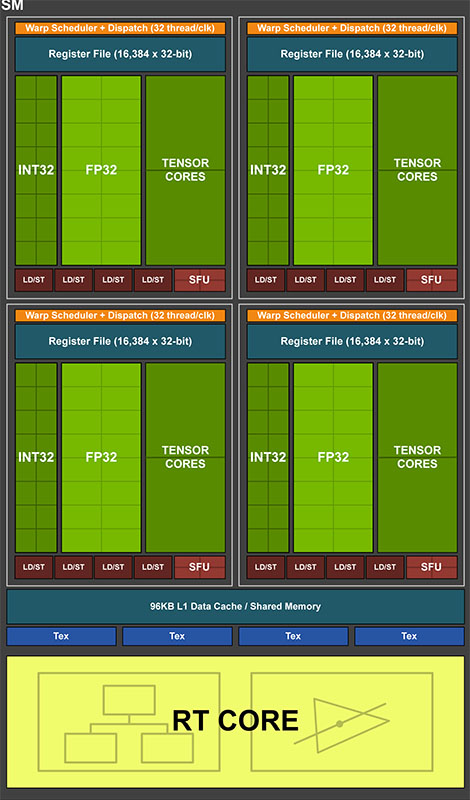
TuringのSM処理ブロックの構成はFP32ユニット×16とINT32ユニット×16で、SMあたりではクロックあたり64のFP32と64のINT32演算の同時実行が可能でした。
AmpereではTuringからFP32ユニットが2倍に増えたものの、あくまで「INT32専用だったデータパスがFP32も実行できるようになった」設計なので、2倍の性能になるのはFP32演算だけを実行する場合で、INT32も実行する場合の性能はTuringから増えていません。
中途半端にも思えますが、一般的にゲームなどではFP32関連の処理が大半で整数演算の比率が低いことから、実際の利用シーンに合わせた効率的な性能改善のアプローチになっているらしい。
当然ながら、パフォーマンスの向上は命令の組み合わせによってシェーダーやアプリケーションレベルで異なるものの、レイトレーシングノイズの除去などはFP32スループットが2倍になることで大きく改善するとのこと。
Ampereでは、FP32演算スループットを2倍にするため、データパスも2倍に拡張されており、SMの共有メモリとL1キャッシュの速度が高速化(Ampereは128 byte/clockでTuringは64 byte/Clock)。
L1キャッシュの容量も96 KBから128 KBに増え(33%増)、合計L1キャッシュ帯域幅はRTX 2080 Superの116 GB/sに対してRTX 3080では219 GB/sに拡張されています。
INT32データパスが追加されたのはTuringからで、今時のシェーダワークロードはFFMAや浮動小数点加算(FADD)、浮動小数点乗算(FMUL)といったFP32命令と、データのアドレッシング/フェッチのための整数加算、浮動小数点比較、min/maxなど単純な整数命令が組み合わさっているため、それらを高速に処理するために追加されました。
とはいえ、今回のAmpereでの変化を見るに比率1:1では過剰だったようです。
第2世代RTコアは処理速度が2倍に
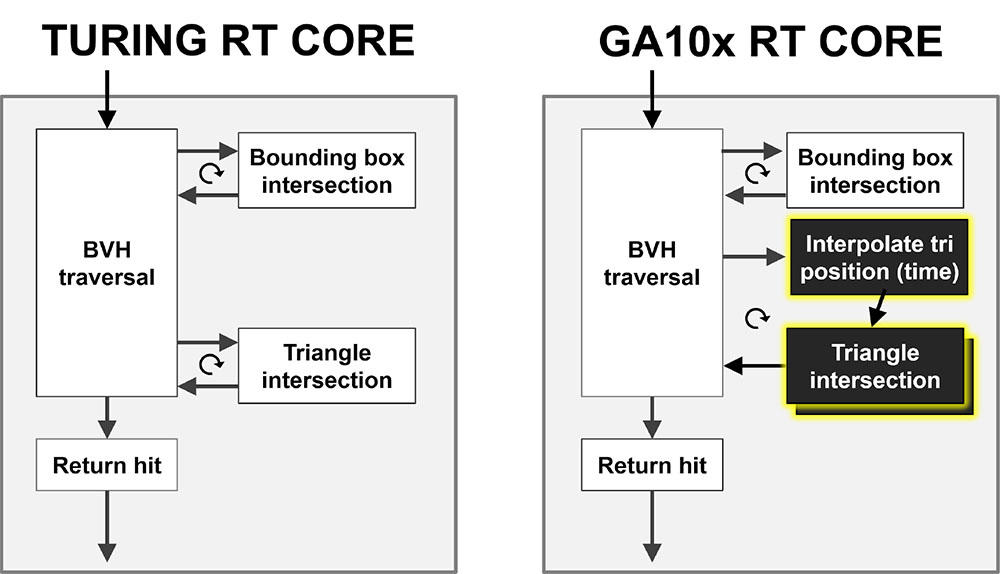
RTコアは、レイトレーシング処理における光線(レイ)がどのポリゴンに衝突するかの計算を高速処理するためのアクセラレータで、階層構造 (BVH: Bounding Volume Hierarchy)を用いて、光線が衝突しそうなポリゴンを効率的に絞り込むための「Bounding Box Intersection」ユニットと、光線がポリゴンにどのように衝突するかを計算する「Triangle Intersection」ユニットの2つを組み合わせたもの。

Ampereで第2世代となったRTコアは、レイトレーシング処理速度が2倍に高速化。Triangle Intersectionのパイプラインが2つに増え、並列処理が可能となったことで処理効率が2倍に向上しています。
さらに計算とグラフィックス処理の同時実行を可能とする非同期計算(SCG: Simultaneous Compute and Graphics)機能が強化され、AmpereではRTコアとグラフィックス、あるいはRTコアと計算処理の同時実行が可能になりました。
Turing以前から計算処理とグラフィックス(シェーディング)の同時処理は可能でしたが、AmpereではRTコアの処理と同時にレイトレーシングノイズ除去アルゴリズム(計算処理)のような処理を実行できます。
RTX 2080 Superでは、CUDAコアでレイトレーシング処理を行った場合に1フレームの描画にかかる時間が51 ms (~20 fps)に対し、RTコアを使った場合20 ms (50 fps)、Tensorコアを組み合わせた場合(要はDLSS有効時)は12 ms (~83 fps)まで短縮できます。
一方RTX 3080では、RTコアの高速化やFP32強化、L1キャッシュ増、GDDR6xメモリ搭載などの効果で、シェーダ処理で37 ms (27 fps)、RTコア利用で11 ms (91 fps)、DLSS有効&非同期計算で6.7 ms (150 fps)までレンダリング時間を短縮できるとのこと。

レイトレーシングでモーションブラーに対応
またAmpereでは、レイトレーシングのモーションブラー処理が可能になったのも新機能の1つ。
リアルタイムレイトレーシングでモーションブラー処理を行う場合、動いているポリゴンに対してポリゴンがその後のフレームで光線とどう衝突するかを計算する必要があり、第2世代RTコアではTriangle Intersectionユニットの前段に「Interpolate Triposition」ユニットが追加され、その処理をハードウェアで実行できるようになりました。
個人的には、モーションブラーは基本的にゲーム内設定でOFFにしてしまう(視認性が落ちるのと見た目が鬱陶しい)のでどうでも良い内容ですが、3Dモデラーには嬉しい機能なのかもしれない。
Sparseモデリングに対応した第3世代Tensorコア
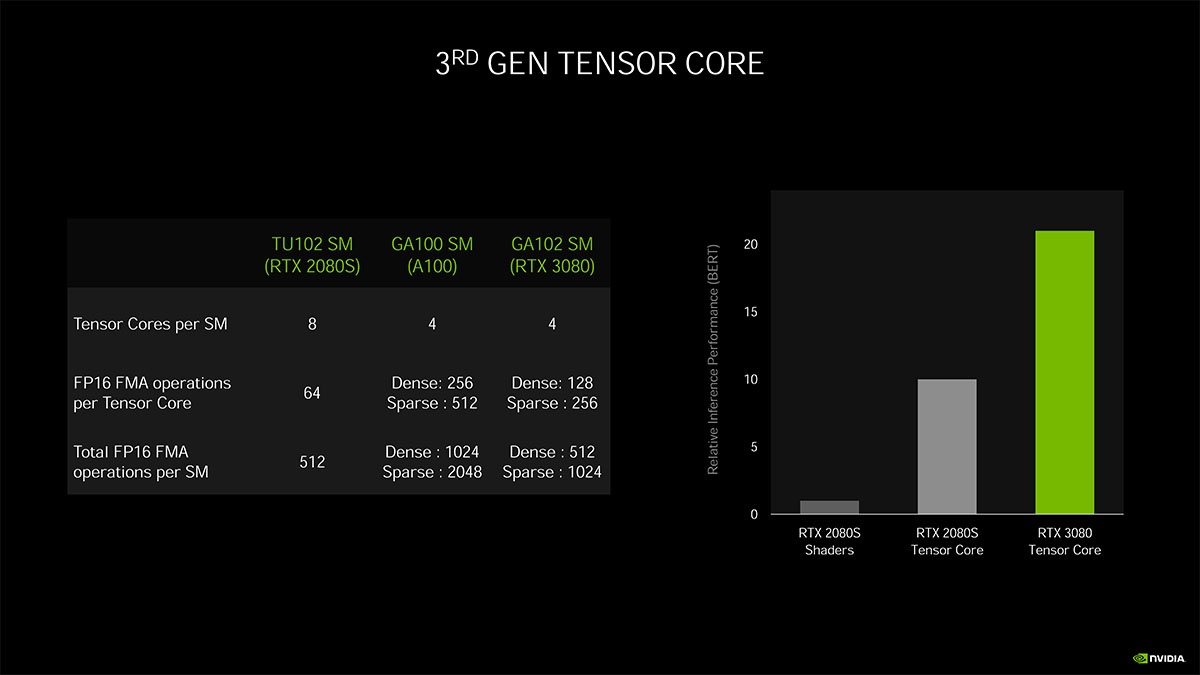
深層学習処理向けの演算ユニットであるTensorコアは、Volta / Turingに続いてAmpereで第3世代へ更新。
第3世代Tensorコア最大の特徴は、推論処理でPruning(刈り込み)によるSparseネットワークに対応する点。
Pruningは推論処理で負荷やメモリ量を減らすため、ニューラルネットワークの中で重要度が低いパラメータを削除する最適化のテクニックで、Ampereの実装ではデータと計算量を半分に削減できます。そのため、Sparseニューラルネットワークを用意すれば、推論処理の性能が2倍になります。
ハードウェア実装としては、VoltaやTuringではSM処理ブロックあたりTensorコア×2が配置されていたのに対し、Ampereでは×1に減っています。
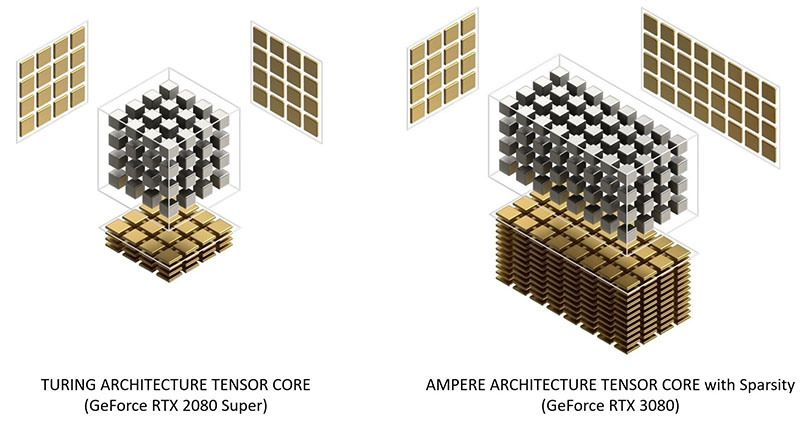
が、第2世代(Turing)TensorコアがFP16の積和算(FMA)を1クロックあたり64並列で処理できる一方で、第3世代Tensorコアでは2倍の128並列で処理できるため、TuringがSMあたり512並列、Ampereも512並列で、演算規模は同じ。
ちなみにGA100は、さらに倍の1クロックあたり256並列で、SM毎1,024並列、Sparseで2,048並列というAI特化な仕様。
なおRTX 3090/80/70ともに前世代からSM数が増えているので、前世代よりもFP16演算性能は高く、そこからSparse最適化で2倍にできるためかなりの改善になっています。
GDDR6から帯域が2倍になったGDDR6X
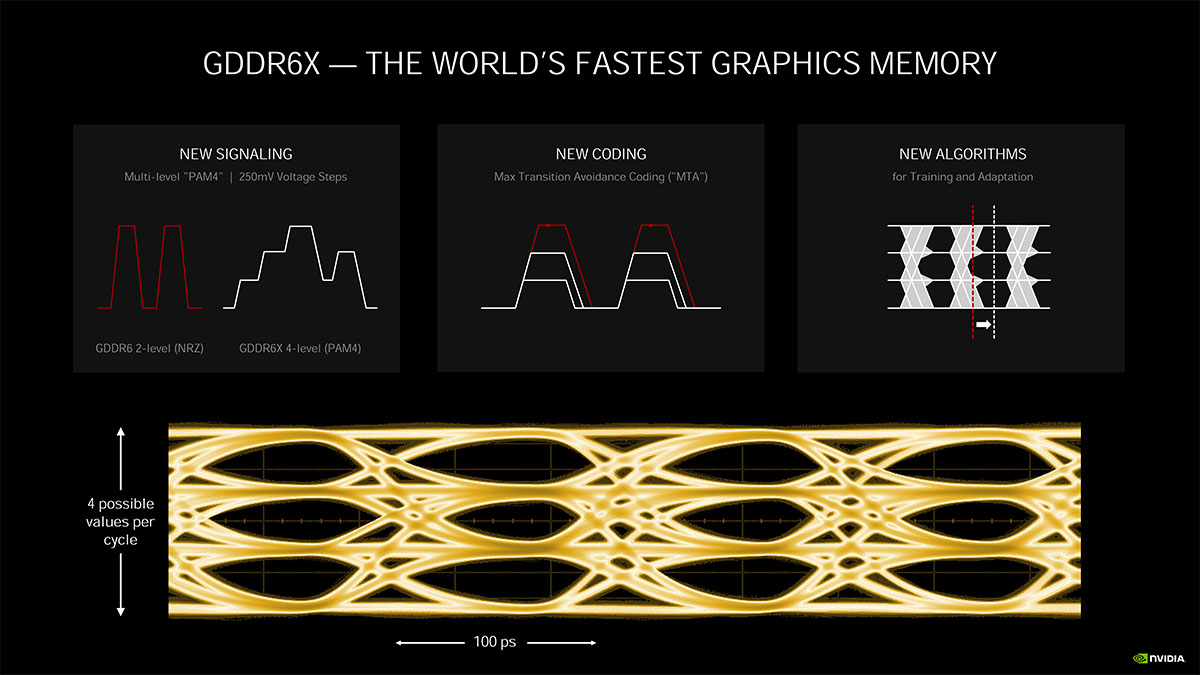
RTX 3090/80では、VRAMに「GDDR6X」を採用。GA102では、HBM2にも迫る900 GB/s超の帯域幅を実現し、TU102から50%以上高速化。
GDDR6XはMicron生産で、開発にあたってもNVIDIAと協力している。GDDR6XはGDDR6と同じデータアクセス粒度、モジュールサイズを維持しつつ、データレートと転送効率が向上しているとのこと。
高速化の鍵となるのが信号伝送技術と「4レベルのパルス振幅変調(PAM4)」で、PAM4マルチレベルシグナリングによってクロックサイクルごとに2-bitのデータを転送できるようになり、GDDR6以前の「PAM2/NRZシグナリング」方式からデータレートが2倍に拡張されています。
PAM4では、クロックサイクルごとに2つのバイナリビットのデータを送信するのではなく(クロックの立ち上がりのエッジで1-bit/下降のエッジで1-bit)、4つの異なる電圧レベルをつかって、エンコードされた2-bitをクロックエッジごとに送信します。電圧レベルは250 mV毎に分割され、各レベルは2-bitデータを表し、DDRと同じく各クロックエッジで00/01/10/11が送信されます。
従来のエンコーディング技術では、PAM4シグナリングでSN比(信号対雑音比)の問題が発生するため、GDDR6Xでは「MTA (Maximum Transition Avoidance)」と呼ぶ新しいエンコーディング方式が採用されています。
メモリOCを想定したエラー検出機能を搭載

関連して、GDDR6Xのメモリインターフェースには、メモリの過剰なオーバークロックでクラッシュやハングアップしてしまうパターンを減らす「Error Detection and Replay (EDR)」と呼ぶ新機能が追加。
EDRは、GDDR6Xのデータリンクを保護するCRCチェックでデータ伝送のエラー発生を検知すると、エラー中の伝送は正常なメモリトランザクションが発生するまで再試行されるというもの。クラッシュを防ぐための機能であり、過剰なOCでエラーが多く発生すると再試行されたトランザクションが実効メモリ帯域幅を喰ってしまうので、性能は低下します。
逆に性能が下がっている場合は、「限界までOCしてしまっている」ということなので、NVIDIAとしてはメモリOCが詰めやすくなると言っている?っぽい。
色々2倍になったAmpere、最適化に期待
Ampereは単なるTuringシュリンク版ではなく、ハードウェアの設計から見ると色々と手が入っているのが分かったので、あとは最適化に期待したいところ。とくにFP32とINT32のあたりはゲーム側で上手いこと使えれば速くなりそうです。


コメント