










数日間苦戦しておりました。
Web系をいじるのは慣れません。
ブログの検索順位を取得するツールをPythonで自作してみようとチャレンジしています。
前回は、Pythonの導入からGoogle検索するまでをやってみました。

今回はこの続きで、検索して得られたよくわからない文字列から、必要な部分のみ取り出すところを作っていきます。
しかし、これがなかなか上手くいきませんでした・・・
Web屋さんなら当たり前の知識がないので、問題の解決に2日もかかってしまいました・・・
 けろたん
けろたん時間かかり過ぎでしょ
ね。いい経験になりましたよ(汗)
今回の重要な点をまとめておくと、
- BeautifuSoupを使ってHTMLデータを解析
- タグ<a>で検索にヒットしたタイトルとURLを取り出す
- リクエストの際にヘッダーにブラウザ情報を入れないと正常なHTMLが返ってこない
これだけ読んでも何言ってるかわからないですね。
下で説明していきます。
Google検索した結果からタイトルとURLを取り出す
前回は、Google検索を実行した結果の文字列を取得しました。
取得した文字列から、欲しい部分(ヒットした記事のタイトルとURL)を抜き出す部分を作っていきます。
やり方は、調べたらだいたいみんな同じ構文を使っていたので、それを使用してみます。
BeautifulSoupライブラリのインストール
Google検索をし、ヒットした記事タイトルとURLを取得するには、
- Requests
- BeautifulSoup
のライブラリが必要です。
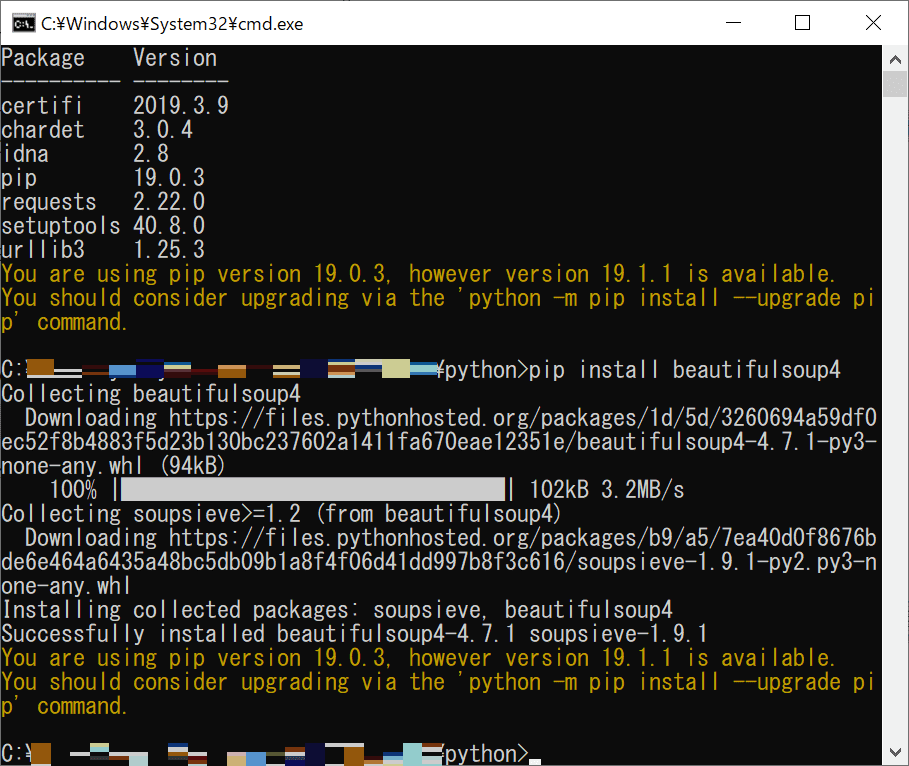
「Requests」は前回インストール済みなので、「BeautifulSoup」の方をインストールします。
「BeautifulSoup」はHTMLの構文を解析するために使用します。

ソースコード
検索結果からヒットした記事タイトルとURLを取得するソースコードです。
やり方は、いろいろなページで紹介されているやり方と同じです。
キーワード「理系夫婦」で10件検索してみます。
ソースコード:search_getTitleURL.py
import requests as web
import bs4
#検索キーワード
keyword = '理系夫婦'
#ひとまず上位10件まで検索結果を取得
url = 'https://www.google.co.jp/search?hl=ja&num=10&q=' + keyword
#接続
response = web.get(url)
#HTTPステータスコードをチェック(200以外は例外処理)
response.raise_for_status()
#取得したHTMLをパース
soup = bs4.BeautifulSoup(response.text, 'html.parser')
#検索結果のタイトルとリンクを取得
ret_link = soup.select('.r > a')
title_list = []
url_list = []
for i in range(len(ret_link)):
# タイトルのテキスト部分を取得
title_txt = ret_link[i].get_text()
# リンクのみを取得し、余計な部分を削除する
url_link = ret_link[i].get('href').replace('/url?q=','')
title_list.append(title_txt)
url_list.append(url_link)
#検索結果を表示
for i in range(len(title_list)):
print(title_list[i])
print(url_list[i])
print('')検索URL
url = ‘https://www.google.co.jp/search?hl=ja&num=10&q=’ + keyword
今回は上位10件のみ検索したかったので、「num=10」としましたが、100件検索したい場合はここの数字を「num=100」に変えればOK
HTTPステータスコードのチェック
きちんとページにアクセスできたかを知るため、HTTPステータスコードをチェックします。
参考のページ:PythonでWebページを取得できたかどうかのエラーチェックと安全な中止の仕方
response.raise_for_status()
こちらのコードでHTTPステータスコードをチェックし、正常(200番)以外の場合は例外処理をしてくれます。
この1行で済んでしまうなんて、便利!
BeautifulSoupでHTML解析
ここの部分のコードです。
#取得したHTMLをパース
soup = bs4.BeautifulSoup(response.text, 'html.parser')
#検索結果のタイトルとリンクを取得
ret_link = soup.select('.r > a')「BeautifulSoup」でHTMLタグ情報を解析しインスタンスを作成します。
Google検索結果ページのHTMLを「右クリック→ページのソースを表示」で見てみると、ヒットした記事タイトルとURLは
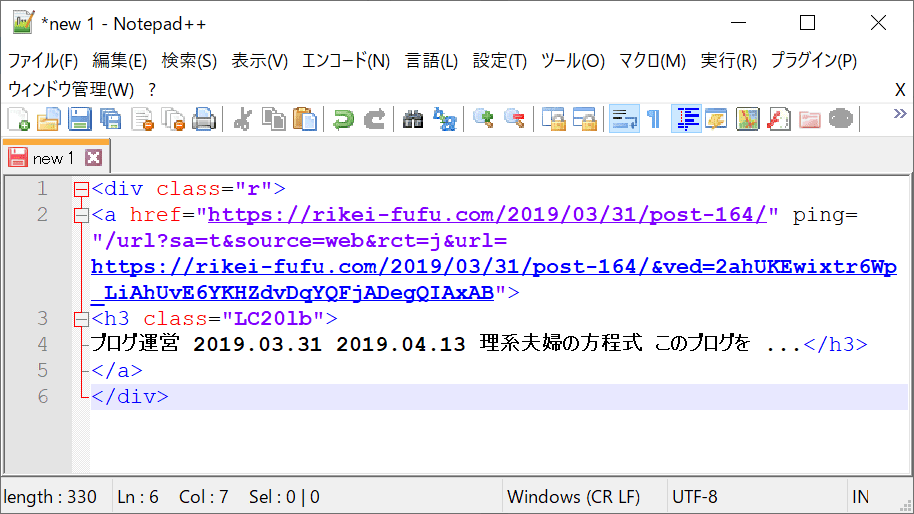
となっているので、class=”r”の下のaタグの情報を「select」で取得します。
このあたりはこのページを参考にしました。:PythonのrequestsとBeautifulSoupでGoogle検索結果から、タイトルとURLと説明文だけを抜き取る
あとは、抜き出したタイトルとURLをリストに入れて表示しています。
実行結果
では、上記のコードを実行してみましょう。
ほとんど、参考ページと同じコードなので、うまくいくはず!
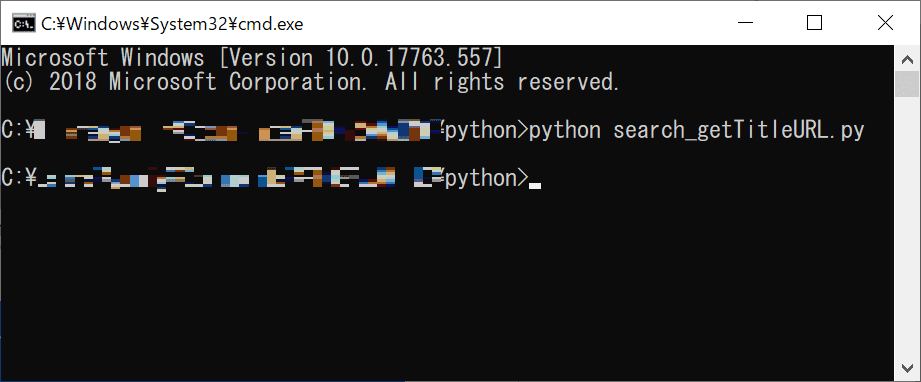
・・・・・・あれ?
なにも表示されません。なぜ??
検索にヒットした記事タイトルとURLが取り出せない・・・
なぜGoogle検索結果の記事タイトルとURLが取り出せないのか・・・?
原因追及の旅が始まりました。
他のHPなら取り出せる
まず疑ったのはselectのタグ指定がおかしいのかということ。
試しにh3タグを指定して
ret_link = soup.select('h3')として実行してみましたが、やはり何も表示されない・・・。
しかし、Google検索以外のページだと、h3タグが表示されていることが発覚!
例えば、Wikipediaのトップページのh3タグを抜き出してみると、
と、きちんとh3タグを取得できています。
じゃあ、なんでGoogle検索結果はうまく取得できないの??
Google検索結果のHTMLがおかしい
Google検索結果のタグが取得できないのは何故なのか?
ここで以下のソースコード
response = web.get(url)
print(response.text)で、検索結果を取得したHTMLを全て表示させてみました。
すると、こんなHTMLだったのです!
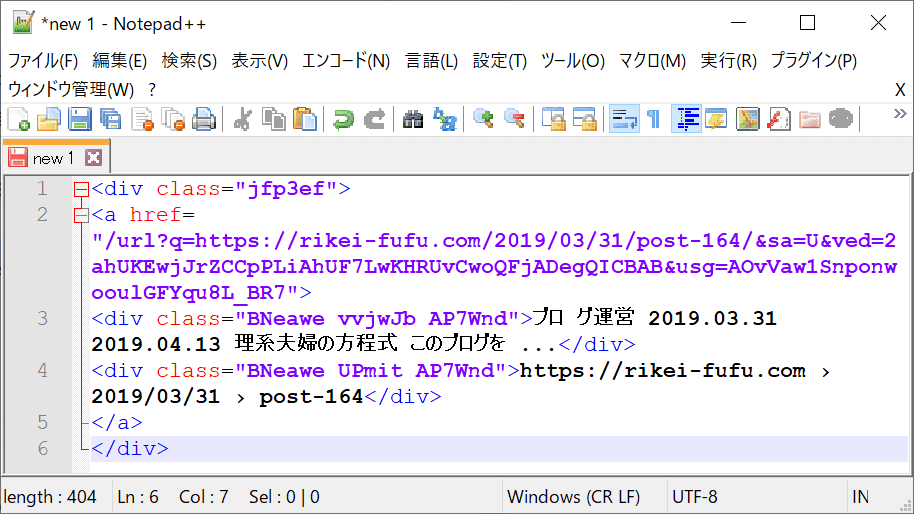
本来(右クリック→ページのソースを表示)のHTMLなら
となっています。
そう、HTMLタグのclass名が違っていたのです!
だから記事タイトルとURLを取得できていないのか。
原因はわかりました。
ちなみに、この原因にたどり着くまでに1日かかりました。
そして原因の解決策を見つけるのに、さらに1日費やしました。
解決策
なんでHTMLタグのclassが変わってしまうのか。
その理由と解決策を調べても、なかなか見つけられませんでした。
文字化け? ⇒ 文字コードをいじってみる ⇒ 違った
など、苦戦。
しかし、やっと、やっと、解決策が見つかったのです(泣)
ブラウザを模擬する
Google検索結果のHTMLのclass名が変になってしまう件の解決方法は、以下のページが参考になりました。
ブラウザリクエストを偽造するためにPythonリクエストを使用する方法
Googleはブラウザからの閲覧なら正常なHTMLを返しているが、わけわからんプログラムからの閲覧にはHTMLの中身を変えているっぽいです。
なので、プログラム上でブラウザを模擬する必要があったのです。
そのブラウザの模擬方法は、参考ページにもあるように、headers情報の「User-Agent」を
ページをgetする際に 追加すればよいとのこと。
ソースコード
修正したソースコードは以下です。
ソースコード:search_getTitleURL2.py
import requests as web
import bs4
#検索キーワード
keyword = '理系夫婦'
#リクエストヘッダー
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"}
#ひとまず上位10件まで検索結果を取得
url = 'https://www.google.co.jp/search?hl=ja&num=10&q=' + keyword
#接続
response = web.get(url, headers=headers)
#HTTPステータスコードをチェック(200以外は例外処理)
response.raise_for_status()
#取得したHTMLをパース
soup = bs4.BeautifulSoup(response.content, 'html.parser')
#検索結果のタイトルとリンクを取得
ret_link = soup.select('.r > a')
title_list = []
url_list = []
for i in range(len(ret_link)):
# タイトルのテキスト部分を取得
title_txt = ret_link[i].get_text()
# リンクのみを取得し、余計な部分を削除する
url_link = ret_link[i].get('href').replace('/url?q=','')
title_list.append(title_txt)
url_list.append(url_link)
#検索結果を表示
for i in range(len(title_list)):
print(title_list[i])
print(url_list[i])
print('')8行目を追加したのと、14行目のgetの引数を追加しただけです。
実行結果
Requestsのヘッダーを追加して実行してみた結果は
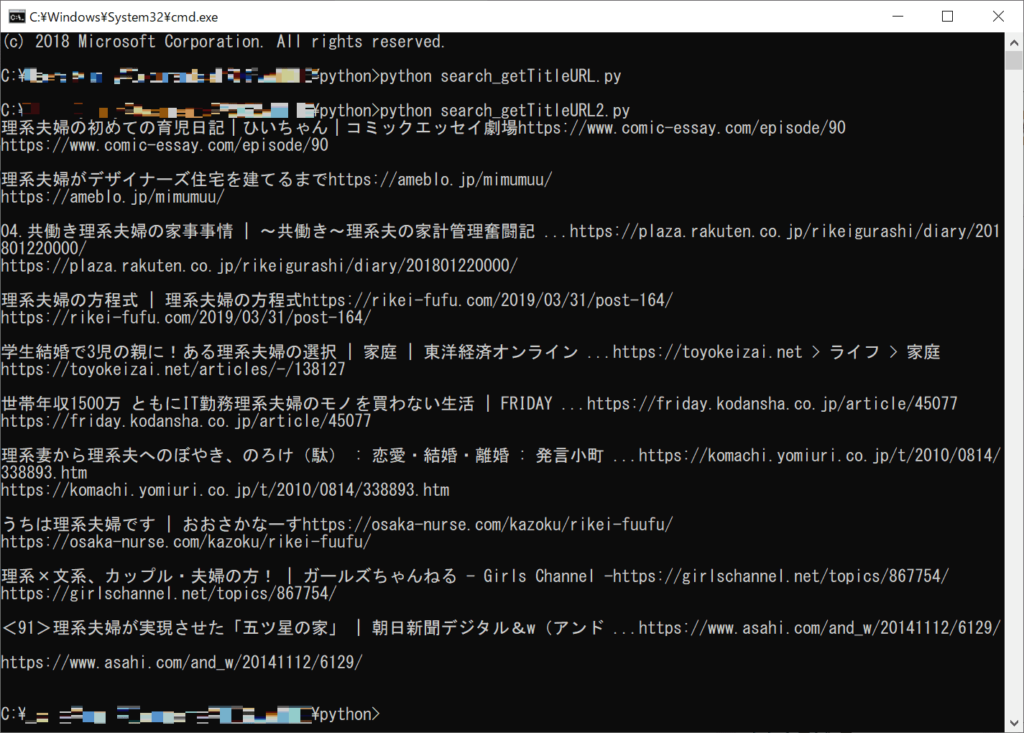
うまくいきました!!!
これを表示するのに2日もかかるとは(涙)
ということで、今回分かった重要ポイントは
でした。
解決の糸口を見つけるための検索は難しいですね。
というのも、最初は「Python Google検索結果 HTML おかしい」とかで検索してましたが、まぁ欲しい情報はでてきません。
「Python requests HTML ブラウザと違う」で、やっと解決策が見つかりました。
ブログ検索順位取得ツールを作るための残りの作業は
- 自分のブログの検索順位を調べる
- 検索キーワードを一覧にしたファイルを読み込む
- 検索順位を調べた結果をCSVにまとめる
- グラフを作る
あたりがあります。
検索する重要部分はできるようになったので、あとはサクッとできてほしい。
んじゃ、また~
おススメのプログラミング独学方法はこちらの記事にまとめました!






コメント