
Seq2Seq(1/4)発明の概要
はぐれ弁理士 PA Tora-O です。今回のテーマとして、ニューラル機械翻訳(NMT)の先駆けとも言える “Seq2Seq” を題材に取り上げていきます。Seq2Seq は、文字列(From Sequence)から文字列へ(To Sequence)の変換モデルを意味します。
背景
従来から、自動翻訳の分野において、登録済みのルールを適用して原文を分析することで訳文を出力する「ルールベース機械翻訳」(RMT)や、対訳データの学習を通じて構築された統計モデルを用いて訳文を出力する「統計的機械翻訳」(SMT)が研究されてきました。
問題の所在
ところが、前者のRMTではルールを登録するための手間や複雑さがあることが、後者のSMTでは翻訳時の計算コストが高いことがそれぞれ問題となっていました。
(→この辺りの課題は、自動翻訳に限られず、ディープラーニング導入前における多くの技術分野に共通することかと思われます。)
解決手段
そこで、Word2Vec の更なる発展形として、ニューラルネットワークを用いた機械翻訳(NMT)を実現する “Seq2Seq” が提案されました。以下、このネットワーク構造の概略的に図示します。
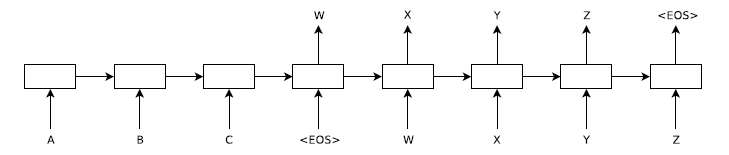
出展:Sequence to Sequence Learning with Neural Networks
本図では解りにくいのですが、このモデルは、2種類の再帰型ニューラルネットワーク(RNN;Recurrent Neural Network)を接続した構造からなります。前段の3ブロックは符号化器(Encoder)として、後段の5ブロックは復号化器(Decoder)としてそれぞれ機能します。そのため、Seq2Seq は、“Encoder-Decoder model” とも呼ばれています。
この Encoder-Decoder model に関して言えば、グーグル翻訳(Google Translate)が商業的成功を収めたこともあって、グーグル社の研究グループが発表した論文(Sutskever et al.)が最も有名です。ところが、この論文によって当該モデルのコンセプトが初めて提案された訳ではなく、この約3か月前に、別の論文(Cho et al.)で既に発表されていました。
[1] Sutskever et al.
Sequence to Sequence Learning with Neural Networks
[2] Cho et al.
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine
両者のモデルの主な相違点は、中間層(隠れ層)の構造にあるようです。具体的には、“Cho et al.” では1層の単純(or 純粋)なRNNを使っていますが、“Sutskever et al.” では4層のLSTM(Long Short-Term Memory)を使っています。これにより、翻訳精度(BLEUスコア)が向上したとの報告がされています。
なお、LSTMは、RNNの一種(改良技術)であり、既に周知技術であるといっても過言ではないと思われます。ただ、Seq2Seq の本質を理解するためにも、少なくともRNNの技術的意義について軽く触れておく必要がありそうです。
以上、今回(第1回)は、“Seq2Seq” について、その背景を含めて説明しました。次回(第2回)は、再帰型ニューラルネットワーク(RNN)の概要について説明します。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。