
SSD (2/3) 実施例の説明
はぐれ弁理士 PA Tora-O です。前回(第1回)では、SSDの概要について説明しました。改めて復習されたい方は、こちらのリンクから確認をお願いします。今回(第2回)は、SSDの実施例について説明します。
RPNとの比較
SSDは、大雑把に言えば、RPN(Region Proposal Network)の完全体と言ってもよいでしょう。RPNの詳細については、以下の記事が参考になります。
Faster R-CNN(3/5)RPNの実施例<前半>
Faster R-CNN(4/5)RPNの実施例<後半>
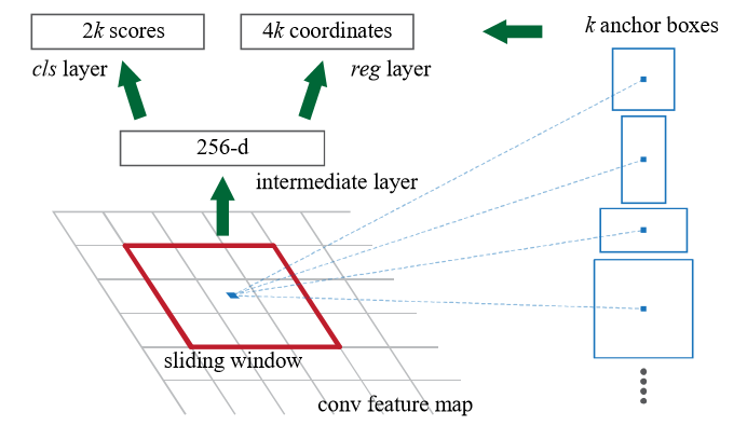
出展:“Faster R-CNN : Towards Real-Time Object Detection with Region Proposal Networks”
RPNでは、特徴マップ内からアンカー(Anchor)を1箇所ずつ順次指定し、ニューラルネットに投入するスライディングウィンドウ法が用いられますが、SSDでは、特徴マップ内にある複数箇所のアンカーに対する検出結果を同時に出力します。
データ構造の特徴
続いて、SSDではどのようなデータが作成されて、物体の検出結果が得られるのかを説明します。
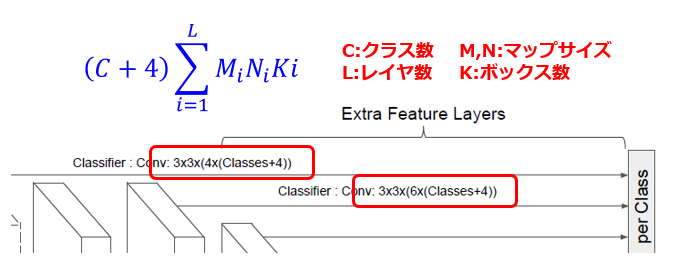
図2は、本論文に記載されたネットワーク構成図を加工した部分拡大図です。本図から理解されるように、各レイヤで段階的に生成された特徴マップに対して畳み込み演算を行って、推定結果の信頼度(Confidence)を示す推定データに整形します。レイヤ毎の推定データは、
[1]特徴マップ内のアンカー位置(M・N)毎、
[2]クラス(C)毎、かつ
[3]デフォルトボックス(K)毎の
オフセット値(4)とその信頼度のデータセットの集合体です。これらの推定データを連結(Concatenate)することで、(C+4)ΣMNK 次元のテンソルデータが得られます。
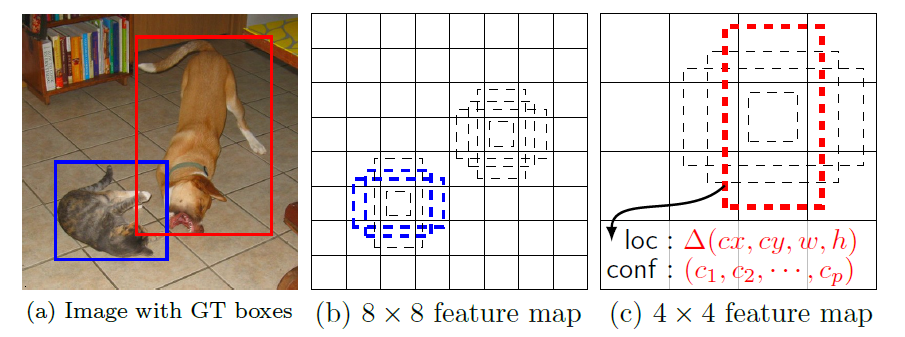
出展:SSD: Single Shot MultiBox Detector
図3は、デフォルトボックス(Default Boxes)の設定方法を模式的に示しています。デフォルトボックスは、RPNのアンカーボックスと実質的に同じです。しかし、RPNでは1種類のマップサイズに対して固定サイズの境界ボックスを設定するのですが、SSDでは複数種類のマップサイズに対して可変サイズの境界ボックスを設定します。
例えば、特徴マップが高解像度であれば小さいサイズの物体の特徴を捉えやすくなり、特徴マップが低解像度であれば大きいサイズの物体の特徴を捉えやすくなる傾向があります。そこで、多重解像度の特徴マップを個別に用いることで、様々なサイズの物体であっても高精度で検出できるようになります。
以上、今回(第2回)は、SSDの実施例として、主要な特徴であるデータ構造について説明しました。テーマ最終回(第3回)は、過去2回分の検討結果を踏まえ、クレーム骨子を含む発明ストーリーを作成してみます。
↓ブログランキングに参加しています。よろしければ1クリックお願いします。