続ChatGPT調査

なぜ、論文のタイトルでヒットする特許が重要と言えるのか?
これには2つの意味が有り、この論文を理解しパックマンのように飲み込んで
新たな発明を生み出せる技術レベルがあることが担保されている。
もう一つが、論文を早期に捜し出し、試してみる技術力があるということが言えます。
また あまたの単語が有る中でこの語順で表現するのはLLMの推論の通りというのもプレゼンPR時に面白みを感じてもらえる?ところです。
有名論文を基に例を挙げます。
Language Models are Unsupervised Multitask Learners
を全文検索したとき
Languageの次に Modelsが来て
その次にare
その次にUnsupervised
その次にマルチタスク Multitask
その次にLearnersのS付なんんて
が来る確率は、この論文を知らなければ天文学的に低いです。
一般的にこんな語順が使われる以外に、
バックグラウンド処理として論文の存在情報を有していることが疑われます。
また、明細書を書く中で会社名のMETAを入れることはほとんどないため
該当する特許がヒットすると、その論文を踏襲していると言えます。
Large Language Model Meta AI
こちらを含む特許のほとんどが中国企業というのも前回お伝えした通りです。
中国🇨🇳は今では機械的な構造の改良発明を単純に量産しているだけではなく、最先端技術も
どの国よりも取り込んでいて侮れません。
さて、それでは有名になったLLMの根拠論文を一通り見ていきます。
LLMの根拠論文
予めですが、OpenAIとしては特許出願がヒットしませんでした。出自からしても論文特化かもしれません。
さてエポックメーキングなOpenAIのGPT-2から見ていきます。
GPT-2の論文
Language Models are Unsupervised Multitask Learners
こちらを引用している特許の出願人です。

結構何処にでもセールスフォースが出てきていて、それも早期に引用しているから隠れたAI企業です。
続く改良版の論文を見ていきます。
GPT-3の論文
Language Models are Few-Shot Learners
GPT-2を見てグーグルが焦ったという話を聞いたことが有りますからメタを含め競合が引用し合っています。

面白いところとしてはLLMの論文を天下の
MITがバイオインフォマティクスに利用しています。

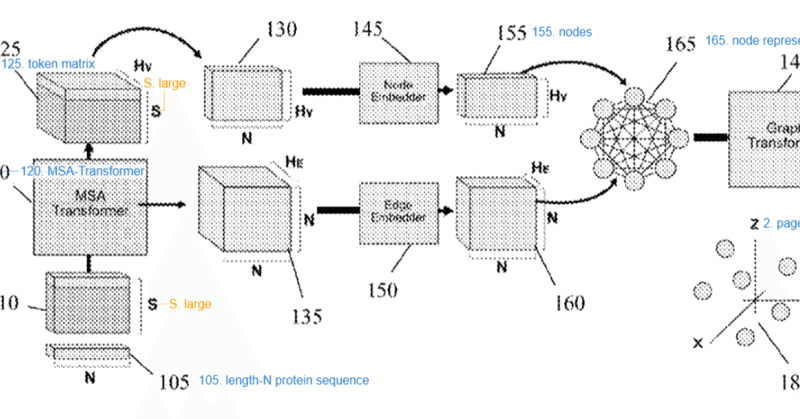
本発明は、タンパク質構造モデリングに関し、特に、タンパク質配列から三次元折り畳み構造のモデルを生成するためにMSAトランスフォーマー埋め込みを使用するグラフアーキテクチャに関する

このように真面目に書かれた明細書では論文の言及があります。
この特許の明細書の中には前回調査で使った下記の論文もしっかり載っています。
トランスフォーマー モデルは、単語のコンテキスト セマンティクスをキャプチャすることが示されているシーケンス ツー シーケンス アーキテクチャです [Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. と Polosukhin, I., “Attention is all you need”, Advances in neuron information processing systems, 30, 2017] であり、言語モデルとして広く展開されています
勿論BERTの基本論文も載っています。
“Bert: Pre-training of deep bidirectional transformers for language understanding”, NAACL HLT 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies—Proceedings of the Conference, 1: 4171-86, 2019; Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., and Amodei, D.
この当たりの発明者の年収が軒並み億超えというのも凄いです。
Bert:
先ほど引用されている論文でもあります。グーグルの製品になります。
Pre-training of deep bidirectional transformers for language understanding
自社引用グーグルを抑えてNTTがトップです。国産LLM期待してます。

その企業のAI能力を測るのに重要なのがどれだけキャッチアップが早いのか

2019年の論文をその年の内に明細書に書いている企業は
ウオッチングしながら継続的に検討をしていたと言えます。

NTTと富士通、NECなど昔の電電公社ファミリーがいますね。
その他 東京大学やソニー、トヨタのヨーロッパ現地法人が1件ずつ出しています。
あと面白いのが母集団736件のうち
Bert:
を冒頭に入れても717件がヒットするという論文ならではの話です。
論文には元々付いていたのですが、言葉の揺れが多そうと除いて検索していました。ちゃんとした企業ばかりなので、有っても誤差程度の差異しか出ません。
グーグルには、他にも最近出したソフトが有りますからお試しします。
LaMDA
Language Models for Dialog Applications
3件うち2件は勿論グーグル
でもグーグル以外がある!!
出願人(権利者)
KARUNYA INSTITUTE OF TECHNOLOGY AND SCIENCES
発明者・インド系
SALAJA SILAS
JOYCE PRINCESS
GETZI JEBA LEELIPUSHPAM PAULRAJ
GRAESON JOSHUA ELIJAH
EVALT R DAVID
2023.09.01
出願日
IN202341058851
出願番号
2023.10.06
最初公開日
代表図がカラーです。

IN202341058851A
公開(公告)番号から明細書と要約のみ抜き出します。
- generating dialogue from the text using Language Model for Dialog Application(LaMDA) followed by voicing out the dialogues with modulation relating to identified/analyzed age, gender and emotions employing voice synthesizer through output unit[3] of the edge device[2].
本発明は、WiFiを介してエッジデバイス[2]に接続されたWiFiユニット[1]を備えた両面ビデオカメラからなる、声のない人々のためのインテリジェント音声支援システムを開示する。 WiFi ユニットを備えた両面ビデオ カメラ[1]は、声の少ない人の前に配置するように適合され、顔の表情のビデオと手のジェスチャーのビデオをキャプチャし、ビデオをエッジ デバイスに送信するように構成されています[2]。 b. エッジデバイス[2]は、クラウドと推論モデル[4]でトレーニングされたコンピューティングシステムで構成され、両面ビデオカメラ[1]からキャプチャされたビデオを受信するように適合され、キャプチャされたビデオから表情フレームと手のジェスチャーフレームを抽出するように構成されています。 MediaPipe フレームワーク、CNN モデル、ViT ベースの CNN、LaMDA を使用して抽出されたフレームを処理するビデオ。エッジ デバイスの出力ユニット [3] を介して音声合成装置を使用して、特定/分析された年齢、性別、感情に関連する変調を伴う対話を音声出力します。 ]。

中国🇨🇳だけでなく次はインドも要注意という話を実感出来る出願です。
最後にメタ
Meta LLaMa
Meta LLaMa
頭文字の反映
Large Language Model Meta AI

何故か中国🇨🇳企業が目立ちます。
まとめ
前回の検索した方法が以外にも反響が大きく、二匹目のドジョウとしてLLM製品の基礎をなす論文をピックアップしました。OpenAI、グーグル、メタの根拠論文なはずなのにいずれも自社引用がトップではないのは面白いです。
まあ、実施可能要件を自社論文を引用するのは最もよく知る企業として気が引けるというのもあるか?
論文を引用しないあり得るところはノウハウなどキレイにぼかして説明できるからというのが特許テクニック的な話かもしれませんけど、憶測の域を出ないですね。
それにしても件数規模では中国に足元にも及ばない日系企業がこうやって詳細に調べるとピックアップ出来るのは、まだまだ捨てたもんじゃないと一安心してます。(競合は有るけど自社が無いのは御愛嬌
この記事が気に入ったらサポートをしてみませんか?