ガチなシャツ
リライブシャツすごすぎワロタwwwwww【リライブシャツを買ってみたらガチだった。】 リライブシャツ 着るだけで「身体機能をサポートする」怪しいシャツがガチだった。 YouTubeやSNSでバズってた「リライブ...

 じょじお
じょじおPower Automate for Desktop(以下:PAD)を使ってPDFや画像から文字を抽出する方法について学習していきたいと思います。
この記事でわかること!
この記事では、PADのTesseractエンジンについて紹介していますが、2021年12月のアップデートによって「Windowsエンジン」という新しいOCRエンジンが選択できるようになりました。Windowsエンジンはデフォルトで日本語が使えますのでTesseractエンジンのように日本語言語ファイルの追加作業は必要ありません。精度についても標準の状態では体感的にWindowsエンジンの方が良さそうです。
先日のWindowsエンジンについては、下記の先日のアップデートの内容紹介記事で使い方を解説しています。よろしければそちらもご参考になさってください。

PDFから文字を読み取るアクションは下記の4つあります。PDFから直接文字を読み取ることのできるアクションと、画像に変換してからでないと文字を読み取ることができないアクションがあります。
OCRグループの中にあるアクションです。この記事で解説しています。
PDFグループの中にあるアクションです。詳細は下記の記事で解説しています。

Googleコグニティブ – ビジョングループの中にあるアクションです。
Microsoftコグニティブ – Computer Visionグループの中にあるアクションです。下記の記事で解説しています。

| アクションが所属するグループ | アクション名 | 読み取る対象 | OCRエンジン | 料金 | 事前準備 |
|---|---|---|---|---|---|
| 「OCR」グループ | OCRを使ってテキストを抽出 | 画像 | Tesseract | 無料 | 日本語化設定必要 |
| 「PDF」グループ | PDFからテキストを抽出 | PDFのみ | ? | 無料 | |
| 「Googleコグニティブ」グループ (ビジョングループ) | テキスト検出 | 画像 | Google Cloud Vision API | 従量課金(無料枠あり) | |
| 「Microsoftコグニティブ」グループ(Computer Visionグループ) | OCR | 画像 | Microsoft Cognitive Services Computer Vision | 従量課金(無料枠あり) |
じょじおこの記事では、無料で使えるTesseract(テッセラクト)エンジンを使ったOCRの実装方法について解説します。
オープンソースのため無料で使えるというメリットがあります。Power Automate for Desktopでもアクションに組み込まれているため、最初から無料で使えます。
2021年12月現在、他のアクションと比較すると一目で差がわかるくらいには精度が低いです。精度を求めるならMicrosoftやGoogleのOCR技術を利用することを検討した方が良いでしょう。しかし、Tesseractも数か月に1回アップデートがされているのでこれから精度が向上していく可能性はあります。
MicrosoftとGoogleのOCR技術はデフォルトで日本語に対応していますが、Power Automate for DesktopのTesseractエンジンは、標準では日本語に対応していません。そのため、自分で日本語ファイルを追加する必要があります。日本語対応の方法についてはこの記事で解説します。
じょじおTesseractエンジンは無料で気軽に利用できる反面、精度が低いという難点があります。精度を求める場合はMicrosoftコグニティブグループのComputer Visionアクションなどを使いましょう。
 ぽこがみさま
ぽこがみさまMicrosoftの『Computer Visionを使った文字起こし』については、下記の記事で解説していますので参考になさってください。
 じょじお
じょじお先にお伝えしましたように、PADのTesseract エンジンは標準では日本語の読み取りに対応していません。日本語文章を抽出する場合は、事前に日本語関連ファイルをインストールします。
多言語対応版:Tesseract at UB Mannheim – GitHub
https://github.com/UB-Mannheim/tesseract/wiki
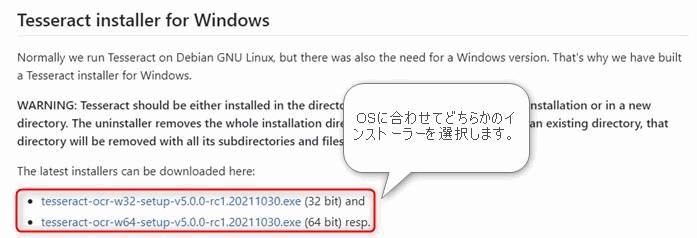
▲日本語関連ファイルは、上のリンク先のWebページ(マンハイム大学図書館さんが公開するGitHub)からダウンロードが可能です。リンク先のページに図のようにTesseract-ocr-w〇〇-setup-v#.#.#.******というファイルリンクが2つありますのでどちらかをダウンロードしてください。
使用しているパソコンのシステムが32ビットの場合はw32を選択し、64ビットの場合はw64を選択します。自分のパソコンがどちらかわからない場合は後述するシステムのビット数の調べ方をご確認ください。
また、このページに置かれているファイルはその時点で最新のバージョンのファイルとなります。現在の最新バージョンはv5.0.0ですのでファイル名もそのようになっていますが、今後この数字は変更になる可能性があります。その時点での最新版をインストールすれば良いかなと思います。
ちなみに私がDLしたバージョンは52,270KBというファイルサイズでした。大きいファイルなのでDLに少し時間がかかかるかもしれません。
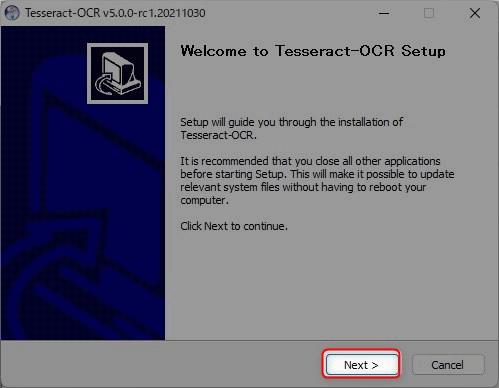
▲ダウンロードしたexeファイルをダブルクリックして実行します。上図の画面は「Next」をクリックして次の画面に進みます。
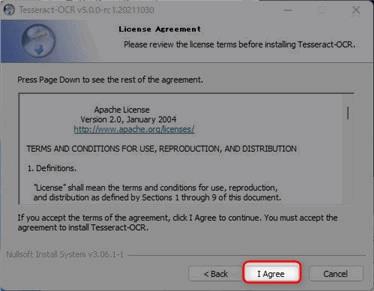
▲同意事項の文章に目を通し「I Agree(同意)」をクリックします。
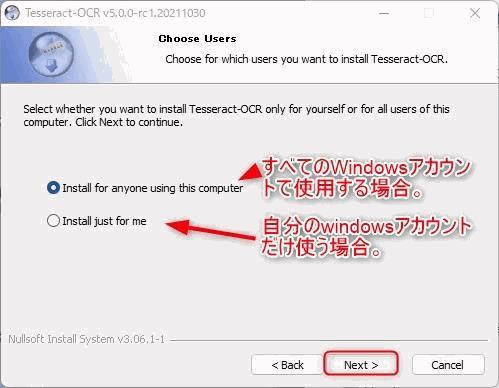
▲使用しているPCのどのWindowsアカウントにインストールするかを指定して「Next」をクリックします。
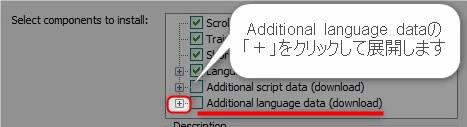
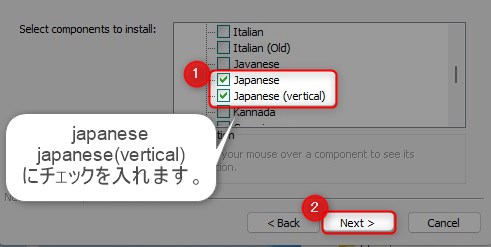
インストールする言語ファイルを選択します。日本語読み取りに必要なファイルは下記の4つです。4つにチェックを入れて「Next」をクリックします。
ちなみにverticalという名前のファイルは縦書きに対応する為のファイルらしいです。
必要な言語ファイル
じょじおわたしは「javanese(ジャワ語)」を間違えて選択しそうになりました。皆さまもお気付けください!
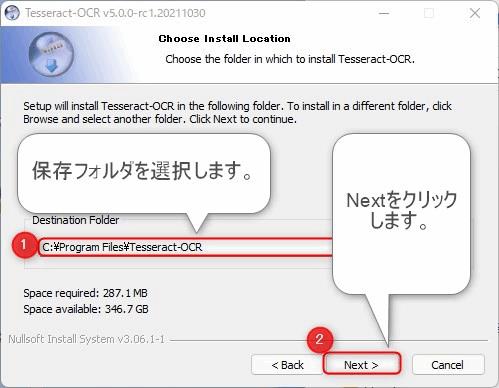
▲保存先のフォルダを選択します。
ここで指定するフォルダは、のちほどPower Automate Desktopでフローを作成するときに必要な情報となります。どこのフォルダにインストールしたかを忘れないようにしましょう!
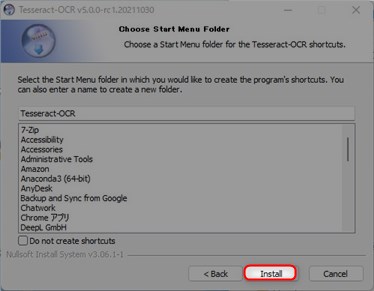
▲インストール内容の確認画面が表示されますので問題がなければ「Install」をクリックしてインストールを開始します。
▲インストールが完了すると図の画面が表示されます。「Finish」ボタンをクリックして画面を閉じてください。
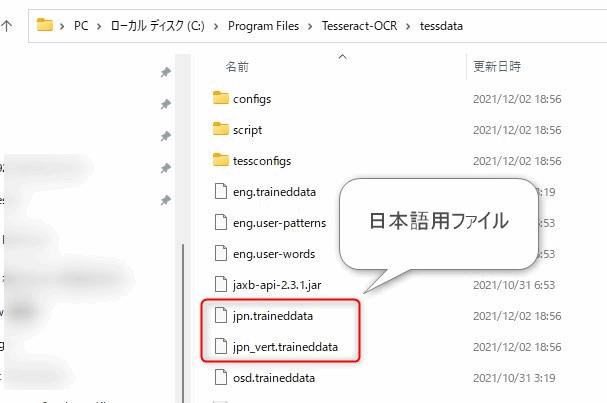
▲Languageファイルは[インストールに指定したフォルダ]\tessdata\の中にあります。
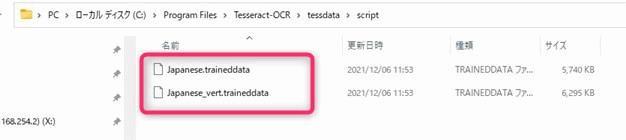
▲Scriptファイルは[インストールに指定したフォルダ]\tessdata\script\の中にあります。
じょじお4つのファイルが確認できました。これでTesseractの日本語化セットアップは完了です。
上で紹介したマンハイム大学図書館で公開されている言語ファイルですが、多くの日本人のWebサイトで紹介されていたのでわたしも使いました。しかし正直なところ日本語精度が悪いので、他に精度の高い日本語言語ファイルを公開しているところがあればそちらを使った方が良いと思います。
じょじお日本語化できましたのでフローを作っていきましょう!!!今回使用するPDFは下図です。

▲Excelで標準で利用できるテンプレートの中の「青色の請求書」というテンプレートを使っています。
作成する処理の流れ
「OCRを使ってテキストを抽出」アクションに直接指定できるファイルは画像形式のファイルだけで、PDFを直接指定することができません。このため、PDFを読み取る場合は一度別のアクションを使ってファイルを開いて表示させる必要があります。そのあと、「OCRを使ってテキストを抽出」 アクションは画像としてPDFを認識して文字を抽出します。

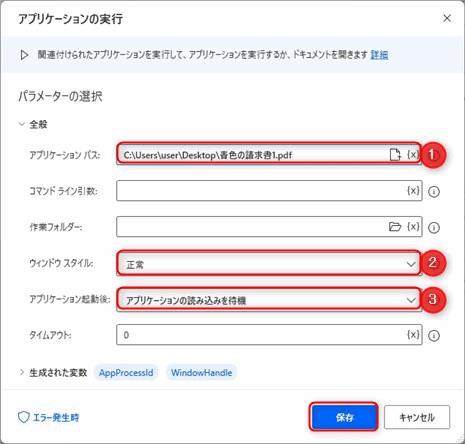
▲システムグループの中にある「アプリケーションの実行」アクションを追加します。下記のようにパラメータを入力します。
ウインドウサイズは最小や非表示にすると読み取りできません。文字を大きく表示した方が精度があがりそうなので全画面にしています。ただし全画面にすると抽出したい箇所が見切れてしまう可能性があります。その場合はウインドウのスクロール処理を追加するなどの工夫が必要です。
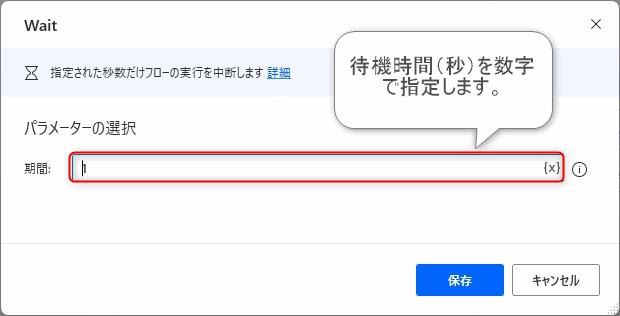
「フローコントロール」グループの中にある「Wait」アクションを追加します。「期間」に待機する時間を秒単位で指定します。今回は1秒待機しようと思いますので1と入力します。
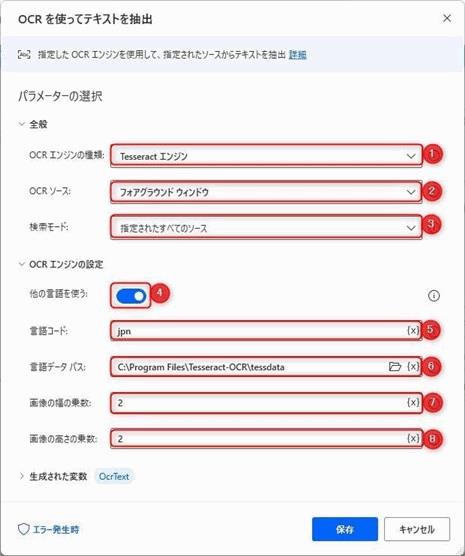
▲「OCR」グループの中にある「OCRを使ってテキストを抽出」アクションを追加してパラメータを入力します。
Tesseractエンジンを選択します。2021年12月現在使用できるエンジンはTesseractエンジンのみになります。
下記の中から選択します。
デフォルトで対応している言語(英語・ドイツ語・スペイン語・フランス語・イタリア語)以外を利用する場合はチェックをオンにします。日本語の場合もチェックをオンにします。
(日本語を選択するには本記事STEP1の日本語化設定が必要です。)
日本語の場合はjpnと入力します。
STEP1日本語化設定で言語ファイルをインストールしたフォルダの中のtessdataのパスを入力します。
例:C:\Program Files\Tesseract-OCR\tessdata
数字を指定します。
数字を指定します。
画像の乗数については下記を参考にしてください。
画像の乗数は画像のサイズを大きくし、テキストの抽出や検索をより効果的におこなえるようにします。 3 より大きい値を設定すると、誤った結果が生じる可能性があることに注意してください。
(抜粋)公式リファレンス:https://docs.microsoft.com/ja-jp/power-automate/desktop-flows/actions-reference/ocr#getting-started-with-ocr-actions
1でうまく読み込めない場合、2に調整してみるとよいかもしれません。3より大きい数字にすると誤認識が発生する可能性があるとドキュメントに記載がありましたので注意して調整してみてください。
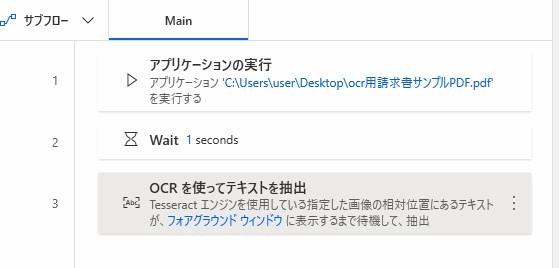
▲フローが完成しました。本来は業務で使用する場合は開いたPDFを閉じるアクションを入れるのですが、今回はテストのため省略します。
フローを実行すると、PDFが開きフローが完了します。
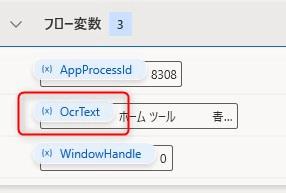
抽出結果は、フローデザイナー画面の左側のフロー変数のところに表示されているOcrText変数の中に入っています。この変数は「OCRを使ってテキストを抽出」アクションが生成する変数です。
変数の中を確認するには変数名の部分をダブルクリックしましょう。結果については次の項で確認してみたいと思います。もし、この変数の中身が空っぽの場合、アクションが正常に動作していない可能性があります。2つのアクションのパラメータを確認してみてください。
 じょじお
じょじお下記がフローの実行結果です。
ホーム ツール 青色の請求書pdf * @ 邊ウン 回交④昌上G@⑤⑨⑳ぐっ2 0 NANDOO 世・ の あみ四人@ 「プキストを幼集」を検索 [了 PDFを書き出し ン マウ 主 PDFを編集 を JIS 仙 PDFを作成 て 請求書 No 100 還 コト gao 縛 アイルを結合 請求先 件名 + にお ベー整理 マ にCr %入 アイルサイズを縮小 し| 金額 ご 3ooooo 。 墨消し , セリティ設定 Adobe Sign 2 っooo ae | 必 入力と署名 Me | [生コントを依頼 COのWNWccE入かCSS その他のツール ごの績に関してご相明な点がございました5下記までお賠い合わせくださし。 人名、電番号メール アドしス ようし<お紹いutします
じょじお精度が低い以前に違和感を感じる・・・、と思ったらPDFを開くときに利用したAdobe Acrobat Readerのメニュー名やタブ名を一緒に抽出しちゃっていました・・・
ぽこがみさまPDFの場合、別の検索モードを指定した方がいいかもしれないにゃ・・・
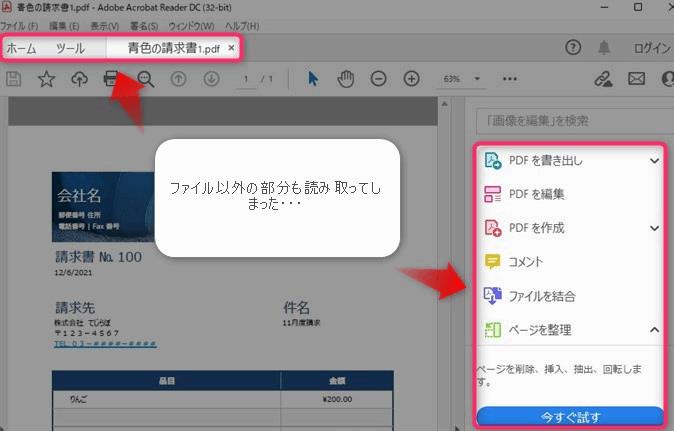
実行結果を見てみると、PDFファイルの外側のAdobe Acrobat Readerのメニューの文字まで読み取ってしまうという想定外の動きになりました。「OCRを使ってテキストを抽出」アクションの検索モードを「指定されたすべてのソース」に指定すると、このように無駄な部分まで読み取ってしまうようです。
実際の業務では、PDF文章まるごとというよりは、PDF文章の一部だけほしい状況の方が多いと思うので検索モードを変更して抽出箇所を絞った方が良さそうだなと思いました。
文章の一部抽出は今回の内容よりも少し難易度が上がります。また機会があれば紹介したいと思います!
アクションを使ってみて気づいた問題点
余分な部分も読み取ってしまう件の対策案
▼PDFを全文抽出するなら「PDFからテキストを抽出」アクションの方が精度が断然上でした。
今のところ、部分抽出を行う場合は「」、全文抽出を行う場合は「PDFからテキストを抽出」
じょじおPDF以外にも画像ファイルを読み取ってみました。↓図をターゲットにしてみます。



画像形式のファイル(jpg/pngなど)の場合は、「OCRを使ってテキストを抽出」アクションに直接渡すことができます(上図の③番)。このため、事前に別のアクションを使ってファイルを開く必要はありません。
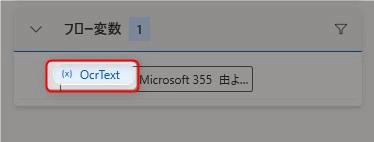
▲フローの実行結果であるOcrText変数をダブルクリックして確認してみましょう。
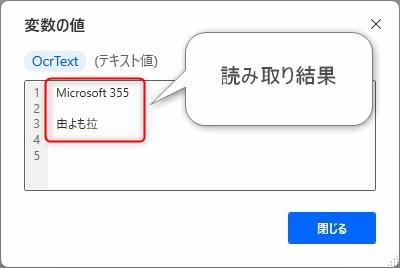
▲OCRの結果が表示されます。
▼結果
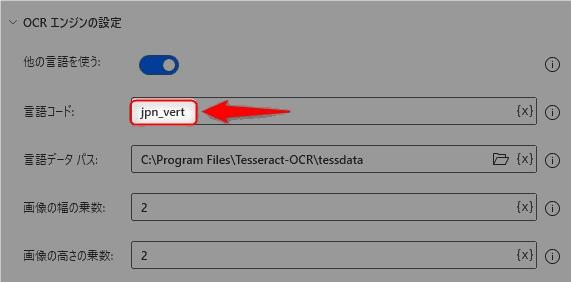
縦書きの文字をターゲットにする場合は、「OCRを使ってテキストを抽出」アクションの「言語コード」のパラメータにjpn_vertと指定します。これはSTEP1でインストールした日本語縦書きファイルjpn_vert.traineddataのファイル名とリンクしています。
 じょじお
じょじお以上、この記事ではPower Automate for Desktopを使ってPDFファイルを文字起こしする方法のひとつである「OCRを使ってテキストを抽出」アクションの使い方について解説しました。
ぽこがみさま次回はPDFの部分抽出にトライしてみようと思います。よろしければ次の記事もご覧ください。

